
Clasificador de razas de la Tierra Media
En este artículo vamos a crear una red neuronal que nos sirva de clasificador de imágenes para algunas de las razas que habitan la tierra media.
Vamos a crear un dataset de imágenes de 5 razas del universo Tolkien: Orcos, Elfos, Enanos, Hobbits y Magos.
El principal problema que tenemos, es que contamos con un reducido número de imágenes, unas 200 de cada raza. Para solucionar esto, vamos a utilizar dos técnicas:
- Transfer Learning -> Entrenar con tan pocas imágenes es un problema, ya que el modelo tiene pocos ejemplos para su aprendizaje, por lo que utilizaremos la red neuronal preentrenada “mobilenet_2”. Eliminaremos la capa de salida e incluiremos una nueva que se adapte a nuestro modelo.
- Data Augmentation -> Aunque contemos con una red preentrenada muy potente, necesitamos entrenar la última capa. Así que utilizaremos esta técnica con la generaremos un mayor número de imágenes para nuestro entrenamiento.
Una vex hayamos entrenado nuestro modelo haremos algunas predicciones usando imágenes de prueba.
Comencemos con el ejercicio
1. Creación del dataset
Para crear nuestro dataset, vamos a buscar las imágenes directamente en google. Haremos una búsqueda por cada una de las razas y nos descargaremos todas las imágenes fácilmente con la extensión de Chorme Download All Images.
Tras esto limpiaremos nuestras imágenes, eliminando duplicados y borrando las que no nos sirvan para nuestro entrenamientos. Yo he seleccionado exactamente 200 por cada raza.
Os dejo las imágenes que he utilizado en mi repositorio.
2. Descarga y preparación de los datos
Tengo las imágenes en el drive, así que permito acceder a mis archivos desde colab.
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
Tras esto, entro en cada carpeta y descomprimo los archivos zip
!unzip /content/drive/MyDrive/ClasificadorImagenes/Elfos.zip
!unzip /content/drive/MyDrive/ClasificadorImagenes/Enanos.zip
!unzip /content/drive/MyDrive/ClasificadorImagenes/Magos.zip
!unzip /content/drive/MyDrive/ClasificadorImagenes/Orcos.zip
!unzip /content/drive/MyDrive/ClasificadorImagenes/Hobbits.zip
Revisamos que la descarga haya sido correcta, mostrando el número de imágenes en cada carpeta.
#Mostrar cuantas imagenes tengo de cada categoria
!ls /content/Elfos | wc -l
!ls /content/Magos | wc -l
!ls /content/Orcos | wc -l
!ls /content/Hobbits | wc -l
!ls /content/Enanos | wc -l
200
200
200
200
200
Una vez comprobado que la descarga ha sido correcta, elimino la conexión con drive.
drive.flush_and_unmount()
Vamos a ver alguna imágenes a ver qué pinta tienen.
# Utilizaremos pyplot
import os
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
plt.figure(figsize=(15,15))
carpeta = '/content/Hobbits'
imagenes = os.listdir(carpeta)
for i, nombreimg in enumerate(imagenes[:25]):
plt.subplot(5,5,i+1)
imagen = mpimg.imread(carpeta + '/' + nombreimg)
plt.imshow(imagen)

Instalamos 2 librerías que vamos a necesitar.
!pip install split-folders
!pip install pytest-shutil
Vamos a utilizar la librería splitfolders para separar nuestras imágenes en train, test y validación. Esta librería coge todas las carpetas que haya y crea 3 carpetas nuevas por cada una de ellas con la proporción de imágenes que le indiquemos.
Como tenemos la carpeta “sample_data” que se genera automáticamente y no la necesitamos, la vamos a eliminar previamente.
import shutil
shutil.rmtree('/content/sample_data') # Eliminamos la carpeta sample_data
Tras esto, hacemos la división de las imágenes entre train, validation y test.
import splitfolders
splitfolders.ratio('/content', output = "dataset", ratio=(0.78, 0.2, 0.02)) # Haremos copia de la imágenes y las dividiremos en 3 carpetas dentro de "dataset".
Copying files: 1003 files [00:00, 5322.86 files/s]
Comprobamos una carpeta para ver que se haya realizado correctamente.
!ls /content/dataset/train/Elfos | wc -l
!ls /content/dataset/val/Elfos | wc -l
!ls /content/dataset/test/Elfos | wc -l
156
40
4
Se ha creado un archivo .config en cada una de las carpetas. Los eliminamos porque sino aparecerían como una clase más e interferiría en el entrenamiento.
!rm -rf /content/dataset/train/.config
!rm -rf /content/dataset/val/.config
!rm -rf /content/dataset/test/.config
3. Data Augmentation
Está técnica se basa en la creación de nuevas imágenes partiendo de los datos antiguos con los que contamos. En este caso haciendo zoom de las imágenes, reescalandolas, realizando un flip horizontal, etc…
Vamos a utilizar ImageDataGenerator para crear nuestros generadores de imágenes para los sets de entrenamiento y validación, aunque en la validación lo único que haremos será reescalar las imágenes.
#Aumento de datos con ImageDataGenerator
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
#Crear el dataset generador
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range = 30,
width_shift_range = 0.25,
height_shift_range = 0.25,
shear_range = 15,
zoom_range = [0.5, 1.5],
#validation_split = 0.2 -> En este caso no modificamos las imágenes de validación.
)
validation_datagen = ImageDataGenerator(rescale=1. / 255)
#Generadores para sets de entrenamiento y pruebas
data_gen_train = train_datagen.flow_from_directory('/content/dataset/train', target_size=(224,224),
batch_size=32, shuffle=True)
data_gen_val = validation_datagen.flow_from_directory('/content/dataset/val', target_size=(224,224),
batch_size=32, shuffle=True)
Found 780 images belonging to 5 classes.
Found 200 images belonging to 5 classes.
Vamos a imprimir unas imágenes aleatorias para ver como funciona nuestro generador.
#Imprimir 10 imagenes del generador de entrenamiento
for imagen, etiqueta in data_gen_train:
for i in range(10):
plt.subplot(2,5,i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(imagen[i])
break
plt.show()

4. Creación del modelo
Lo primero que vamos a hacer es buscar en tensorflow hub la red mobilenet_2. En este caso nos facilitan las cosas y tenemos la red ya empaquetada pero sin la capa de salida. Es el modo “feature_vector”.
La descargamos.
import tensorflow as tf
import tensorflow_hub as hub
url = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4"
mobilenetv2 = hub.KerasLayer(url, input_shape=(224,224,3))
Para no desaprovechar el entrenamiento que se ha realizado con esta red, congelamos todas las capas entrenadas.
mobilenetv2.trainable = False
Creamos nuestro modelo con la red que nos hemos descargado añadiendo una capa densa de salida, de 5 neuronas, con activación softmax que es la que se suele utilizar en los casos de clasificación.
modelo = tf.keras.Sequential([
mobilenetv2,
tf.keras.layers.Dense(5, activation='softmax')
])
Vemos el resumen del modelo que hemos creado.
modelo.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer (KerasLayer) (None, 1280) 2257984
dense (Dense) (None, 5) 6405
=================================================================
Total params: 2,264,389
Trainable params: 6,405
Non-trainable params: 2,257,984
_________________________________________________________________
Compilamos nuestro modelo. Utilizamos el optimizador adam, para la función de pérdida seleccionamos categorical_crossentropy y por último como métrica accuracy.
modelo.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
Antes de entrenar nuestro modelo definimos un par de callbacks para intentar afinar nuestro modelo.
Incluimos EarlyStopping para que al pasar más de 8 epochs sin que la función de pérdida disminuya, el entrenamiento se detenga. También incluimos ReduceLROPlateau para que modifique la tasa de aprendizaje pero en este caso en 4 epochs.
from keras.callbacks import EarlyStopping, ReduceLROnPlateau, ModelCheckpoint, Callback
early_stop = EarlyStopping(monitor='val_loss', patience=8, verbose=1, min_delta=1e-4)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=4, verbose=1, min_delta=1e-4)
callbacks_list = [early_stop, reduce_lr]
Entrenamos nuestro modelo durante 50 épocas.
#Entrenar el modelo
EPOCAS = 50
historial = modelo.fit(
data_gen_train,
epochs=EPOCAS,
batch_size=32,
validation_data=data_gen_val,
callbacks=callbacks_list
)
Epoch 1/50
25/25 [==============================] - 29s 553ms/step - loss: 1.6465 - accuracy: 0.3064 - val_loss: 1.2034 - val_accuracy: 0.4800 - lr: 0.0010
Epoch 2/50
25/25 [==============================] - 13s 517ms/step - loss: 1.2504 - accuracy: 0.4962 - val_loss: 0.9545 - val_accuracy: 0.6400 - lr: 0.0010
Epoch 3/50
25/25 [==============================] - 13s 518ms/step - loss: 1.0655 - accuracy: 0.5564 - val_loss: 0.8287 - val_accuracy: 0.6900 - lr: 0.0010
Epoch 4/50
25/25 [==============================] - 16s 654ms/step - loss: 0.9625 - accuracy: 0.6333 - val_loss: 0.7622 - val_accuracy: 0.7300 - lr: 0.0010
Epoch 5/50
25/25 [==============================] - 13s 521ms/step - loss: 0.8724 - accuracy: 0.6641 - val_loss: 0.7374 - val_accuracy: 0.7200 - lr: 0.0010
Epoch 6/50
25/25 [==============================] - 13s 517ms/step - loss: 0.8747 - accuracy: 0.6474 - val_loss: 0.6525 - val_accuracy: 0.7600 - lr: 0.0010
Epoch 7/50
25/25 [==============================] - 13s 515ms/step - loss: 0.8304 - accuracy: 0.6603 - val_loss: 0.6433 - val_accuracy: 0.7600 - lr: 0.0010
Epoch 8/50
25/25 [==============================] - 13s 525ms/step - loss: 0.7791 - accuracy: 0.7192 - val_loss: 0.6277 - val_accuracy: 0.7800 - lr: 0.0010
Epoch 9/50
25/25 [==============================] - 13s 529ms/step - loss: 0.7142 - accuracy: 0.7500 - val_loss: 0.6079 - val_accuracy: 0.7850 - lr: 0.0010
Epoch 10/50
25/25 [==============================] - 13s 518ms/step - loss: 0.6840 - accuracy: 0.7321 - val_loss: 0.6077 - val_accuracy: 0.7550 - lr: 0.0010
Epoch 11/50
25/25 [==============================] - 13s 513ms/step - loss: 0.7069 - accuracy: 0.7282 - val_loss: 0.5746 - val_accuracy: 0.7950 - lr: 0.0010
Epoch 12/50
25/25 [==============================] - 13s 523ms/step - loss: 0.6649 - accuracy: 0.7500 - val_loss: 0.5767 - val_accuracy: 0.8000 - lr: 0.0010
Epoch 13/50
25/25 [==============================] - 13s 521ms/step - loss: 0.6841 - accuracy: 0.7474 - val_loss: 0.5574 - val_accuracy: 0.7850 - lr: 0.0010
Epoch 14/50
25/25 [==============================] - 13s 519ms/step - loss: 0.6286 - accuracy: 0.7705 - val_loss: 0.5336 - val_accuracy: 0.8000 - lr: 0.0010
Epoch 15/50
25/25 [==============================] - 13s 519ms/step - loss: 0.6390 - accuracy: 0.7628 - val_loss: 0.5323 - val_accuracy: 0.8100 - lr: 0.0010
Epoch 16/50
25/25 [==============================] - 13s 517ms/step - loss: 0.6009 - accuracy: 0.7833 - val_loss: 0.5202 - val_accuracy: 0.8050 - lr: 0.0010
Epoch 17/50
25/25 [==============================] - 13s 520ms/step - loss: 0.6138 - accuracy: 0.7718 - val_loss: 0.5191 - val_accuracy: 0.8000 - lr: 0.0010
Epoch 18/50
25/25 [==============================] - 13s 521ms/step - loss: 0.6067 - accuracy: 0.7833 - val_loss: 0.5235 - val_accuracy: 0.8250 - lr: 0.0010
Epoch 19/50
25/25 [==============================] - 13s 520ms/step - loss: 0.5915 - accuracy: 0.7821 - val_loss: 0.5250 - val_accuracy: 0.8250 - lr: 0.0010
Epoch 20/50
25/25 [==============================] - 13s 518ms/step - loss: 0.5729 - accuracy: 0.7987 - val_loss: 0.5177 - val_accuracy: 0.8000 - lr: 0.0010
Epoch 21/50
25/25 [==============================] - 13s 517ms/step - loss: 0.5508 - accuracy: 0.7962 - val_loss: 0.5142 - val_accuracy: 0.8000 - lr: 0.0010
Epoch 22/50
25/25 [==============================] - 13s 527ms/step - loss: 0.5802 - accuracy: 0.7885 - val_loss: 0.5322 - val_accuracy: 0.8000 - lr: 0.0010
Epoch 23/50
25/25 [==============================] - 13s 513ms/step - loss: 0.5815 - accuracy: 0.7974 - val_loss: 0.5090 - val_accuracy: 0.8050 - lr: 0.0010
Epoch 24/50
25/25 [==============================] - 15s 614ms/step - loss: 0.5397 - accuracy: 0.8064 - val_loss: 0.5141 - val_accuracy: 0.8200 - lr: 0.0010
Epoch 25/50
25/25 [==============================] - 13s 531ms/step - loss: 0.5252 - accuracy: 0.8103 - val_loss: 0.5360 - val_accuracy: 0.8150 - lr: 0.0010
Epoch 26/50
25/25 [==============================] - 13s 524ms/step - loss: 0.5526 - accuracy: 0.7910 - val_loss: 0.4965 - val_accuracy: 0.8250 - lr: 0.0010
Epoch 27/50
25/25 [==============================] - 13s 517ms/step - loss: 0.5777 - accuracy: 0.7756 - val_loss: 0.4837 - val_accuracy: 0.8150 - lr: 0.0010
Epoch 28/50
25/25 [==============================] - 13s 521ms/step - loss: 0.5323 - accuracy: 0.8000 - val_loss: 0.5096 - val_accuracy: 0.8150 - lr: 0.0010
Epoch 29/50
25/25 [==============================] - 13s 516ms/step - loss: 0.5434 - accuracy: 0.7923 - val_loss: 0.5274 - val_accuracy: 0.8100 - lr: 0.0010
Epoch 30/50
25/25 [==============================] - 13s 512ms/step - loss: 0.5127 - accuracy: 0.8141 - val_loss: 0.5095 - val_accuracy: 0.8250 - lr: 0.0010
Epoch 31/50
25/25 [==============================] - ETA: 0s - loss: 0.4902 - accuracy: 0.8269
Epoch 31: ReduceLROnPlateau reducing learning rate to 0.00010000000474974513.
25/25 [==============================] - 13s 517ms/step - loss: 0.4902 - accuracy: 0.8269 - val_loss: 0.5002 - val_accuracy: 0.8400 - lr: 0.0010
Epoch 32/50
25/25 [==============================] - 13s 516ms/step - loss: 0.4964 - accuracy: 0.8167 - val_loss: 0.4903 - val_accuracy: 0.8500 - lr: 1.0000e-04
Epoch 33/50
25/25 [==============================] - 13s 508ms/step - loss: 0.4725 - accuracy: 0.8333 - val_loss: 0.4877 - val_accuracy: 0.8250 - lr: 1.0000e-04
Epoch 34/50
25/25 [==============================] - 13s 507ms/step - loss: 0.4926 - accuracy: 0.8385 - val_loss: 0.4862 - val_accuracy: 0.8400 - lr: 1.0000e-04
Epoch 35/50
25/25 [==============================] - ETA: 0s - loss: 0.4591 - accuracy: 0.8269
Epoch 35: ReduceLROnPlateau reducing learning rate to 1.0000000474974514e-05.
25/25 [==============================] - 13s 515ms/step - loss: 0.4591 - accuracy: 0.8269 - val_loss: 0.4869 - val_accuracy: 0.8300 - lr: 1.0000e-04
Epoch 35: early stopping
Parece que tras 35 épocas la función de pérdida no disminuye, por lo que el entramiento se detiene.
Vamos a ver gráficamente como se han comportado la función de pérdida y el accuracy con datos de entrenamiento y validación.
#Graficas de precisión
acc = historial.history['accuracy']
val_acc = historial.history['val_accuracy']
loss = historial.history['loss']
val_loss = historial.history['val_loss']
rango_epocas = range(35)
plt.figure(figsize=(8,8))
plt.subplot(1,2,1)
plt.ylim(0, 1)
plt.plot(rango_epocas, acc, label='Precisión Entrenamiento')
plt.plot(rango_epocas, val_acc, label='Precisión Pruebas')
plt.legend(loc='lower right')
plt.title('Precisión de entrenamiento y pruebas')
plt.subplot(1,2,2)
plt.ylim(0, 1)
plt.plot(rango_epocas, loss, label='Pérdida de entrenamiento')
plt.plot(rango_epocas, val_loss, label='Pérdida de pruebas')
plt.legend(loc='upper right')
plt.title('Pérdida de entrenamiento y pruebas')
plt.show()
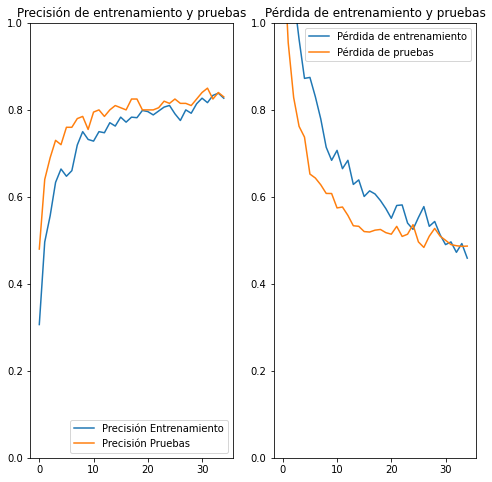
Podemos ver que el modelo se comporta correctamente, llegando a una accuracy de 0.85 con los datos de validación. El modelo nos puede servir.
5. Predicciones
Lo primero que vamos a ver es la etiqueta que se ha asignado a cada una de las razas.
data_gen_train.class_indices
{'Elfos': 0, 'Enanos': 1, 'Hobbits': 2, 'Magos': 3, 'Orcos': 4}
from PIL import Image
import cv2
dicc= data_gen_train.class_indices
for raza in list(dicc.keys()):
test = '/content/dataset/test/' + raza + '/'
lista = os.listdir('/content/dataset/test/'+ raza + '/')
for img in lista:
plt.imshow(mpimg.imread(test + img))
img = Image.open(test + str(img))
img = np.array(img).astype(float)/255
img = cv2.resize(img, (224,224))
prediccion = modelo.predict(img.reshape(-1, 224, 224, 3))
print("La imagen es de " + raza + " y el modelo predice: ", list(dicc.keys())[list(dicc.values()).index(np.argmax(prediccion[0], axis=-1))])
plt.show()
1/1 [==============================] - 1s 720ms/step
La imagen es de Elfos y el modelo predice: Magos

1/1 [==============================] - 0s 19ms/step
La imagen es de Elfos y el modelo predice: Hobbits

1/1 [==============================] - 0s 19ms/step
La imagen es de Elfos y el modelo predice: Elfos

1/1 [==============================] - 0s 20ms/step
La imagen es de Elfos y el modelo predice: Elfos

1/1 [==============================] - 0s 19ms/step
La imagen es de Enanos y el modelo predice: Enanos

1/1 [==============================] - 0s 20ms/step
La imagen es de Enanos y el modelo predice: Enanos
1/1 [==============================] - 0s 20ms/step
La imagen es de Enanos y el modelo predice: Elfos

1/1 [==============================] - 0s 19ms/step
La imagen es de Enanos y el modelo predice: Enanos

1/1 [==============================] - 0s 19ms/step
La imagen es de Hobbits y el modelo predice: Hobbits

1/1 [==============================] - 0s 20ms/step
La imagen es de Hobbits y el modelo predice: Hobbits

1/1 [==============================] - 0s 20ms/step
La imagen es de Hobbits y el modelo predice: Hobbits

1/1 [==============================] - 0s 21ms/step
La imagen es de Hobbits y el modelo predice: Hobbits

1/1 [==============================] - 0s 25ms/step
La imagen es de Magos y el modelo predice: Enanos

1/1 [==============================] - 0s 23ms/step
La imagen es de Magos y el modelo predice: Magos

1/1 [==============================] - 0s 22ms/step
La imagen es de Magos y el modelo predice: Magos

1/1 [==============================] - 0s 22ms/step
La imagen es de Magos y el modelo predice: Magos

1/1 [==============================] - 0s 21ms/step
La imagen es de Orcos y el modelo predice: Orcos

1/1 [==============================] - 0s 22ms/step
La imagen es de Orcos y el modelo predice: Orcos

1/1 [==============================] - 0s 21ms/step
La imagen es de Orcos y el modelo predice: Orcos

1/1 [==============================] - 0s 24ms/step
La imagen es de Orcos y el modelo predice: Orcos

Vemos que las predicciones son bastante acertadas.
Ahora vamos a jugar un poco más con nuestro modelo, y vamos a realizar predicciones con imágenes completamente distintas del dataset original.
Así en cada raza tenemos:
- Elfos -> Una imagen de una persona disfrazada de duende de la navidad.
- Enanos -> Una imagen de Tyrion Lannister, personaje de la serie Juego de Tronos.
- Hobbits -> Una imagen del Homo Floresiensis, un hominido descubierto en Indonesia al que dentro de la comunidad científica se le conoce como el “hobbit” debido a su estatura principalmente.
- Orcos -> Una imagen del personaje de animación Shrek.
- Magos -> Una imagen del mago Merlín de la película de Disney.
Descargamos las imágenes de drive.
from google.colab import drive
drive.mount('/content/drive')
!unzip /content/drive/MyDrive/ClasificadorImagenes/Predict.zip
Archive: /content/drive/MyDrive/ClasificadorImagenes/Predict.zip
inflating: Predict/Elfo.jpg
inflating: Predict/Enano.jpg
inflating: Predict/hobbit.jpg
inflating: Predict/mago.jpg
inflating: Predict/orco.jpg
Realizamos las predicciones, a ver si nuestro modelo es capaz de identificarlas.
test = '/content/Predict/'
lista = os.listdir('/content/Predict/')
for img in lista:
plt.imshow(mpimg.imread(test + img))
img = Image.open(test + str(img))
img = np.array(img).astype(float)/255
img = cv2.resize(img, (224,224))
prediccion = modelo.predict(img.reshape(-1, 224, 224, 3))
print("El modelo predice:", list(dicc.keys())[list(dicc.values()).index(np.argmax(prediccion[0], axis=-1))])
plt.show()
1/1 [==============================] - 0s 21ms/step
El modelo predice: Orcos

1/1 [==============================] - 0s 19ms/step
El modelo predice: Enanos

1/1 [==============================] - 0s 28ms/step
El modelo predice: Hobbits

1/1 [==============================] - 0s 21ms/step
El modelo predice: Hobbits

1/1 [==============================] - 0s 19ms/step
El modelo predice: Magos

Hemos tenido un buen resultado, solo ha fallado al identificar al Elfo, quizás un duende de navidad se asemeja más a un hobbit.
Por último, vamos a ver en qué raza me hubica el modelo.
plt.imshow(mpimg.imread('/content/drive/MyDrive/foto_hector.jfif'))
img = Image.open('/content/drive/MyDrive/foto_hector.jfif')
img = np.array(img).astype(float)/255
img = cv2.resize(img, (224,224))
prediccion = modelo.predict(img.reshape(-1, 224, 224, 3))
print("El modelo predice:", list(dicc.keys())[list(dicc.values()).index(np.argmax(prediccion[0], axis=-1))])
plt.show()

1/1 [==============================] - 0s 43ms/step
El modelo predice: Hobbits
6. Guardar el modelo
Creamos la carpeta para poder exportarla a donde queramos.
!mkdir -p carpeta_salida/modelo_razas
Guardamos el modelo.
modelo.save('carpeta_salida/modelo_razas')
Hacemos un zip de la carpeta para poder transportarlo.
!zip -r modelo_razas.zip /content/carpeta_salida/modelo_razas/
adding: content/carpeta_salida/modelo_razas/ (stored 0%)
adding: content/carpeta_salida/modelo_razas/saved_model.pb (deflated 92%)
adding: content/carpeta_salida/modelo_razas/variables/ (stored 0%)
adding: content/carpeta_salida/modelo_razas/variables/variables.data-00000-of-00001 (deflated 8%)
adding: content/carpeta_salida/modelo_razas/variables/variables.index (deflated 78%)
adding: content/carpeta_salida/modelo_razas/keras_metadata.pb (deflated 81%)
adding: content/carpeta_salida/modelo_razas/assets/ (stored 0%)
Este sería el final del proyecto, espero haya explicado bien las distintas técnicas empleadas