
WEB SCRAPING: Creando nuestra base de datos de palas de padel
En este blog vamos crear nuestra base de datos de datos de palas de padel scrapeando la información de una página web. En este caso existen 49 páginas con 12 palas en cada página, en total tendremos información de más de 580 palas. Nos interesa tener la siguiente información por cada pala:
- Nombre de la pala
- Precio de la pala
- Puntuación de la pala.
- Composición de la pala.
Para este proceso deberemos hacer 2 pasos: 1.- Recorreremos las 49 páginas para obtener los siguientes datos: Nombre de la pala, precio de la pala, puntuación global y link a la página de la pala. 2.- Recorreremos los más de 580 enlaces para obtener la puntuación desglosada y la composición de cada pala.
Comenzamos el proceso
# Importamos librerías necesarias
import pandas as pd
import requests
from bs4 import BeautifulSoup
import time
Vamos a probar en primer lugar a scrapear los datos ‘Nombre’, ‘Puntuación’ y ‘Precio’ de las palas de 1 única página.
# Dirección de la página web
url = "https://padelzoom.es/palas/"
# Hacemos el get requests para leer la información
page = requests.get(url)
# Analizamos la información en formato html
soup = BeautifulSoup(page.content, 'html.parser')
Una vez hemos definido la dirección, hacemos el get de la información y la convertimos en formato html.
Antes de comenzar a obtener la información deseada, tenemos que conocer el nombre del contenedor donde se encuentra. Para esto vamos a la página web y pinchando sobre el botón derecho seleccionamos la opción de inspeccionar.
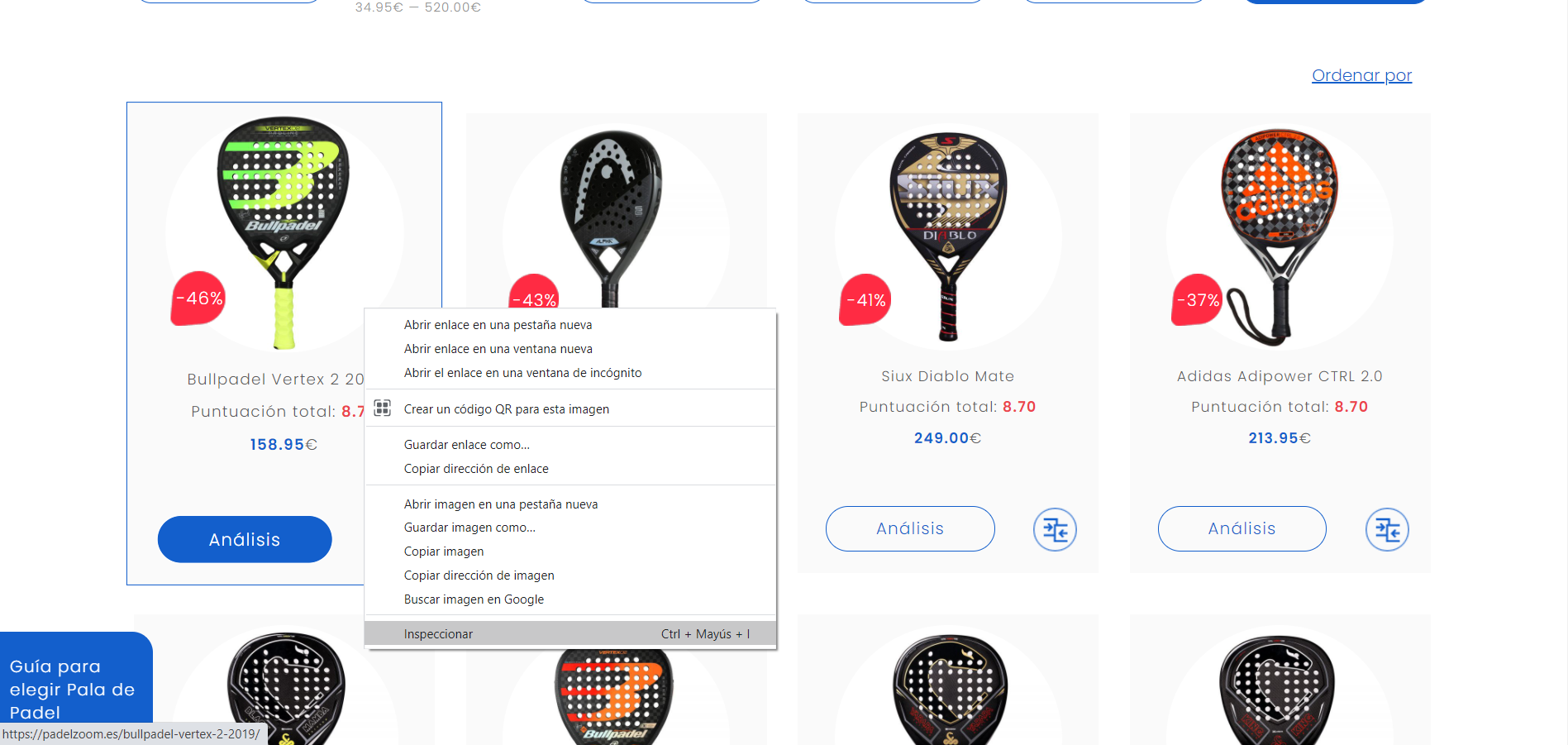
Después buscaremos el nombre del contenedor que contiene la información.
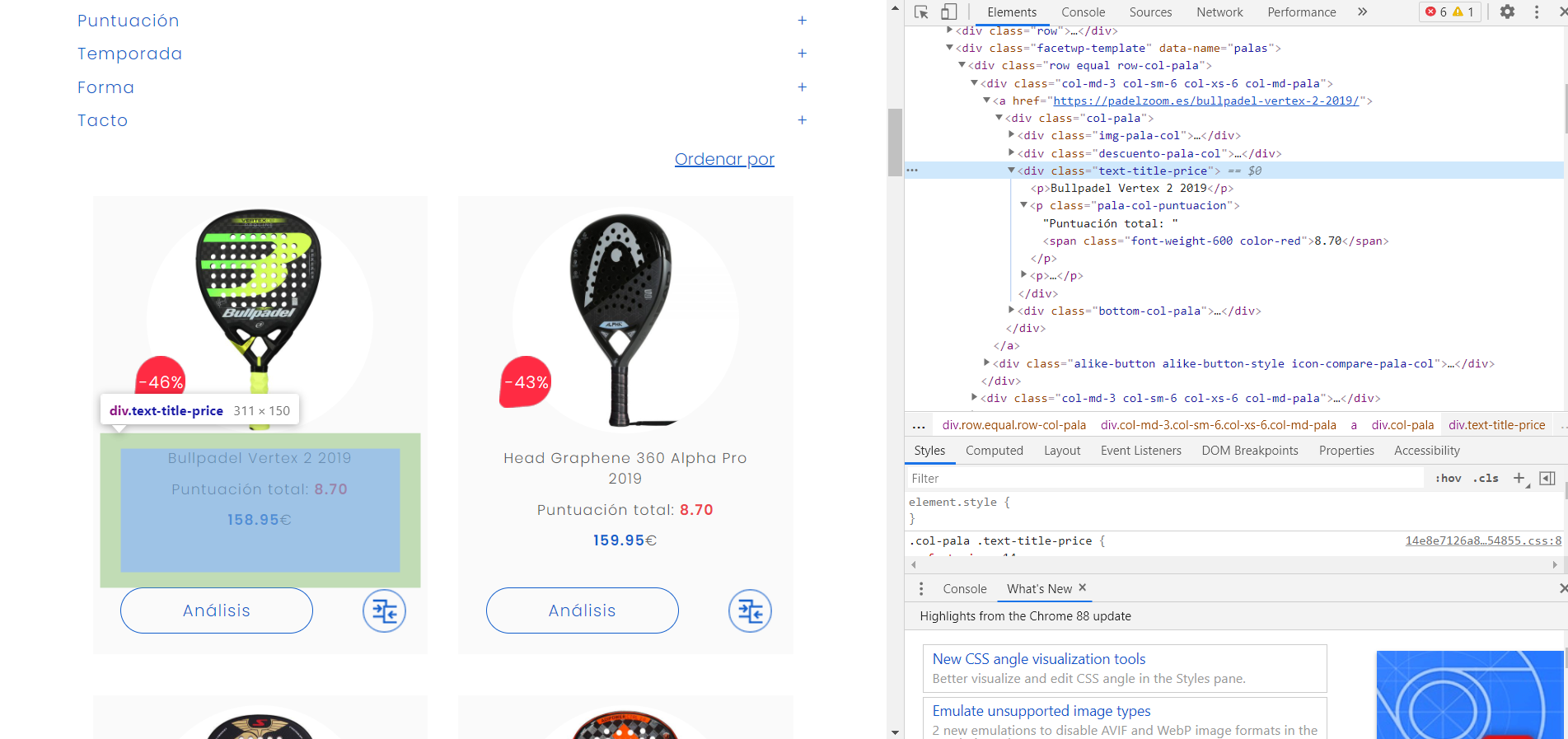
Una vez que sabemos esto podemos empezar con el scraping.
# Buscamos todas las etiquetas de la clase "text-title-price" que es el contenedor de la
# información que estamos buscando
pl = soup.find_all('div', class_="text-title-price")
# Creamos 3 listas vacías para almacenar la información
palas = list()
puntuacion = list()
precio = list()
# Creamos un bucle sobre toda la información que hay en cada contenedor "text-title-price"
# Y añadimos cada tipo de información en su lista.
for i in pl:
a = i.find('p')
b = i.find('span', class_="font-weight-600 color-red")
c = i.find('span', class_="color-blue font-weight-600")
palas.append(a.text)
puntuacion.append(b.text)
precio.append(c.text)
#Unificamos toda la información en una lista única
lista = (palas, puntuacion, precio)
lista
(['Siux Diablo Mate',
'Bullpadel Vertex 2 2019',
'Head Graphene 360 Alpha Pro 2019',
'Adidas Adipower CTRL 2.0',
'Vibora Black Mamba Black Series 1K',
'Bullpadel Vertex 02 2020',
'Vibora Yarara Edition Black Series 1K',
'Vibora King Cobra Black 1K',
'Star Vie Metheora Warrior 2020',
'Alkemia Vento',
'Alkemia Ignis',
'Head Graphene 360 Alpha Pro 2021'],
['8.70',
'8.70',
'8.70',
'8.70',
'8.70',
'8.70',
'8.70',
'8.70',
'8.70',
'8.70',
'8.70',
'8.70'],
['199.00',
'158.95',
'159.95',
'218.95',
'231.95',
'187.90',
'259.50',
'304.50',
'262.50',
'149.00',
'149.00',
'231.90'])
# Convertimos en dataframe
df = pd.DataFrame (lista).transpose()
df.columns = ['Pala','Puntuación','Precio']
df
| Pala | Puntuación | Precio | |
|---|---|---|---|
| 0 | Siux Diablo Mate | 8.70 | 199.00 |
| 1 | Bullpadel Vertex 2 2019 | 8.70 | 158.95 |
| 2 | Head Graphene 360 Alpha Pro 2019 | 8.70 | 159.95 |
| 3 | Adidas Adipower CTRL 2.0 | 8.70 | 218.95 |
| 4 | Vibora Black Mamba Black Series 1K | 8.70 | 231.95 |
| 5 | Bullpadel Vertex 02 2020 | 8.70 | 187.90 |
| 6 | Vibora Yarara Edition Black Series 1K | 8.70 | 259.50 |
| 7 | Vibora King Cobra Black 1K | 8.70 | 304.50 |
| 8 | Star Vie Metheora Warrior 2020 | 8.70 | 262.50 |
| 9 | Alkemia Vento | 8.70 | 149.00 |
| 10 | Alkemia Ignis | 8.70 | 149.00 |
| 11 | Head Graphene 360 Alpha Pro 2021 | 8.70 | 231.90 |
Vemos que hemos obtenido el resultado que queríamos, así que procedemos a scrapear sus enlaces a las páginas de cada pala donde aparecen los detalles de cada una.
# Por otro lado vamos a escrapear los enlaces de las 12 palas que tenemos en esta página
# Le decimos que busque todos enlaces a otras páginas
tags = soup('a')
# Creamos la lista vacía
enlaces = list()
# Le añadimos la subcadena que vamos a utilizar como condición que tienen que tener los enlaces
# para añadir a nuestra lista, ya que hay multiples enlaces y nosotros solo estamos interesados
# en los enlaces a las palas
sub = 'https://padelzoom.es/'
# Añadimos un contador a nuestro bucle ya que hemos detectado que nos interesan solo los 12 primeros
# enlaces de cada página, ya que pertenecen a las 12 palas que hay en cada página. Existen otros enlaces
# que también cumplirían la condición pero no nos interesan.
count = 0
# Lanzamos el bucle
for tag in tags:
b = (tag.get('href'))
if count < 12 and sub in b:
enlaces.append(b)
count += 1
# Comprobamos que tenemos los 12 enlaces que buscamos
enlaces
['https://padelzoom.es/siux-diablo-mate/',
'https://padelzoom.es/bullpadel-vertex-2-2019/',
'https://padelzoom.es/head-graphene-360-alpha-pro-2019/',
'https://padelzoom.es/adidas-adipower-ctrl-2-0/',
'https://padelzoom.es/vibora-black-mamba-black-series-1k/',
'https://padelzoom.es/bullpadel-vertex-02-2020/',
'https://padelzoom.es/vibora-yarara-edition-black-series-1k/',
'https://padelzoom.es/vibora-king-cobra-black-1k/',
'https://padelzoom.es/star-vie-metheora-warrior-2020/',
'https://padelzoom.es/alkemia-vento/',
'https://padelzoom.es/alkemia-ignis/',
'https://padelzoom.es/head-graphene-360-alpha-pro-2021/']
Tras comprobar que efectivamente obtenemos el resultado esperado, creamos la lista de páginas en las que lanzar el scrapeo.
# Ahora vamos a hacer una lista de las 49 páginas en las que tenemos que entrar para hacer el scraping
webs = list()
# Añadimos la primera página a nuestra lista de manera manual ya que tiene un formato distinto
webs.append(url)
# Observamos que el resto de páginas tienen la misma estructura, solo cambia el número de página, por
# lo que podemos crear la lista con un bucle
for i in range(2,50):
webs.append('https://padelzoom.es/palas/?fwp_paged='+ str(i))
# Comprobamos
webs
['https://padelzoom.es/palas/',
'https://padelzoom.es/palas/?fwp_paged=2',
'https://padelzoom.es/palas/?fwp_paged=3',
'https://padelzoom.es/palas/?fwp_paged=4',
'https://padelzoom.es/palas/?fwp_paged=5',
'https://padelzoom.es/palas/?fwp_paged=6',
'https://padelzoom.es/palas/?fwp_paged=7',
'https://padelzoom.es/palas/?fwp_paged=8',
'https://padelzoom.es/palas/?fwp_paged=9',
'https://padelzoom.es/palas/?fwp_paged=10',
'https://padelzoom.es/palas/?fwp_paged=11',
'https://padelzoom.es/palas/?fwp_paged=12',
'https://padelzoom.es/palas/?fwp_paged=13',
'https://padelzoom.es/palas/?fwp_paged=14',
'https://padelzoom.es/palas/?fwp_paged=15',
'https://padelzoom.es/palas/?fwp_paged=16',
'https://padelzoom.es/palas/?fwp_paged=17',
'https://padelzoom.es/palas/?fwp_paged=18',
'https://padelzoom.es/palas/?fwp_paged=19',
'https://padelzoom.es/palas/?fwp_paged=20',
'https://padelzoom.es/palas/?fwp_paged=21',
'https://padelzoom.es/palas/?fwp_paged=22',
'https://padelzoom.es/palas/?fwp_paged=23',
'https://padelzoom.es/palas/?fwp_paged=24',
'https://padelzoom.es/palas/?fwp_paged=25',
'https://padelzoom.es/palas/?fwp_paged=26',
'https://padelzoom.es/palas/?fwp_paged=27',
'https://padelzoom.es/palas/?fwp_paged=28',
'https://padelzoom.es/palas/?fwp_paged=29',
'https://padelzoom.es/palas/?fwp_paged=30',
'https://padelzoom.es/palas/?fwp_paged=31',
'https://padelzoom.es/palas/?fwp_paged=32',
'https://padelzoom.es/palas/?fwp_paged=33',
'https://padelzoom.es/palas/?fwp_paged=34',
'https://padelzoom.es/palas/?fwp_paged=35',
'https://padelzoom.es/palas/?fwp_paged=36',
'https://padelzoom.es/palas/?fwp_paged=37',
'https://padelzoom.es/palas/?fwp_paged=38',
'https://padelzoom.es/palas/?fwp_paged=39',
'https://padelzoom.es/palas/?fwp_paged=40',
'https://padelzoom.es/palas/?fwp_paged=41',
'https://padelzoom.es/palas/?fwp_paged=42',
'https://padelzoom.es/palas/?fwp_paged=43',
'https://padelzoom.es/palas/?fwp_paged=44',
'https://padelzoom.es/palas/?fwp_paged=45',
'https://padelzoom.es/palas/?fwp_paged=46',
'https://padelzoom.es/palas/?fwp_paged=47',
'https://padelzoom.es/palas/?fwp_paged=48',
'https://padelzoom.es/palas/?fwp_paged=49']
Efectivamente se ha creado la lista con los enlaces a las 49 páginas.
Ahora sí, vamos a lanzar un bucle que recorra las 49 páginas y nos scrapee la información de las 588 palas. Finalmente tendremos de cada pala ‘Enlace’, ‘Modelo’, ‘Puntuación’ y ‘Precio’.
# Creamos listas vacías para incluir la distinta información
palas = list()
puntuacion = list()
precio = list()
enlaces = list()
# Creamos un bucle sobre las 49 páginas
for web in webs:
# Vamos a obtener toda la información que hay en cada contenedor "text-title-price"
pl = soup.find_all('div', class_="text-title-price")
# Hacemos el get de cada web
page = requests.get(web)
# Analizamos la información en formato html
soup = BeautifulSoup(page.content, 'html.parser')
# Creamos un bucle sobre la información que tenemos en el contenedor "text-title-price"
# para añadir únicamente la que nos interese
for i in pl:
a = i.find('p')
b = i.find('span', class_="font-weight-600 color-red")
c = i.find('span', class_="color-blue font-weight-600")
palas.append(a.text)
puntuacion.append(b.text)
precio.append(c.text)
# Buscamos todos enlaces a otras páginas
tags = soup('a')
# Añadimos un contador a nuestro bucle ya que hemos detectado que nos interesan solo los 12 primeros
# enlaces de cada página y no el resto aunque cumplan la condición
count = 0
# Añadimos la subcadena que vamos a utilizar como condición para añadir a nuestra lista
sub = 'https://padelzoom.es/'
for tag in tags:
b = (tag.get('href'))
if count < 12 and sub in b:
enlaces.append(b)
count += 1
# Añadimos un time.sleep para no saturar la web
time.sleep(1)
# Unificamos toda la información en una lista única
lista = (palas, puntuacion, precio, enlaces)
# Convertimos en dataframe
df = pd.DataFrame (lista).transpose()
df.columns = ['Pala','Puntuacion','Precio','Enlaces']
# Comprobamos
df
| Pala | Puntuacion | Precio | Enlaces | |
|---|---|---|---|---|
| 0 | Bullpadel Hack 2019 | 8.60 | 179.00 | https://padelzoom.es/siux-diablo-mate/ |
| 1 | Royal Padel Whip Polietileno 2019 | 8.60 | 132.90 | https://padelzoom.es/bullpadel-vertex-2-2019/ |
| 2 | Adidas Adipower 2.0 | 8.60 | 198.95 | https://padelzoom.es/head-graphene-360-alpha-p... |
| 3 | Siux Diablo Granph | 8.60 | 279.00 | https://padelzoom.es/adidas-adipower-ctrl-2-0/ |
| 4 | Siux Diablo Grafeno Azul | 8.60 | 279.00 | https://padelzoom.es/vibora-black-mamba-black-... |
| ... | ... | ... | ... | ... |
| 583 | Adidas V6 | 5.90 | 49.95 | https://padelzoom.es/adidas-v5/ |
| 584 | Adidas V7 | 5.90 | 70.04 | https://padelzoom.es/primeros-pasos-padel/ |
| 585 | Adidas Match Light 3.0 2021 | 5.90 | 54.00 | https://padelzoom.es/padel-pro-shop/ |
| 586 | Varlion LW One Soft 2018 | 6.10 | https://padelzoom.es/mejores-palas-padel-junio... | |
| 587 | Bullpadel Libra 2018 | 6.10 | https://padelzoom.es/star-vie-metheora-warrior... |
588 rows × 4 columns
# Guardamos la información en un excel eliminando el índice
df.to_excel('palas.xlsx',index=False)
Ahora vamos con la puntuación de cada pala
En este segunda fase, vamos a obtener por una lado las características de las palas: ‘Temporada’, ‘Material’, ‘Tacto’,…; y por otro, vamos a obtener la puntuación de la pala: ‘Salida de bola’, ‘Potencia’, ‘Manejabilidad’,…
Probamos a obtener las puntuaciones de la pala Siux Diablo Mate
url2 = 'https://padelzoom.es/siux-diablo-mate/'
# Hacemos el get requests para leer la información
page2 = requests.get(url2)
# Analizamos la información en formato html
soup = BeautifulSoup(page2.content, 'html.parser')
# Buscamos todas las etiquetas de la clase "value-puntuacion" que es el contenedor de la
# información que estamos buscando
pts = soup.find_all('div', class_="value-puntuacion")
# Creamos una lista vacía para almacenar la información
puntos = list()
# Creamos un bucle que recorra cada elemento de la lista webs
for p in pts:
a = p.find('span')
puntos.append(a.text)
# Comprobamos
puntos
['8.70', '9.00', '9.00', '9.00', '8.00', '8.50']
Vemos que hemos obtenido correctamente las puntuaciones de la pala
# En este punto cargamos la tabla 'palas.xslx' que guardamos anteriormente
palas = pd.read_excel('palas.xlsx')
# Rescatamos la columna enlaces para hacer un bucle
enlaces_palas = palas['Enlaces']
enlaces_palas
0 https://padelzoom.es/bullpadel-hack-2019/
1 https://padelzoom.es/royal-padel-whip-polietil...
2 https://padelzoom.es/adidas-adipower-2-0/
3 https://padelzoom.es/siux-diablo-granph/
4 https://padelzoom.es/siux-diablo-grafeno-azul/
...
583 https://padelzoom.es/adidas-v6/
584 https://padelzoom.es/adidas-v7/
585 https://padelzoom.es/adidas-match-light-3-0-2021/
586 https://padelzoom.es/varlion-lw-one-soft-2018/
587 https://padelzoom.es/bullpadel-libra-2018/
Name: Enlaces, Length: 588, dtype: object
Vamos a lanzar el bucle para scrapear las puntuaciones
# Creamos una lista vacía para almacenar la información
puntos = list()
# Y lanzamos el bucle para obtener las puntuaciones
for enlace in enlaces_palas:
url = enlace
page = requests.get(url)
# Analizamos la información en formato html
soup = BeautifulSoup(page.content, 'html.parser')
# Creamos uns lista vacía para almancenar la información de cada página, y que se vacíe
# en cada visita a una nueva página
puntos_pala = list()
# Añadimos el nombre de cada pala en primer lugar
modelo = soup.find('span', property="name")
puntos_pala.append(modelo.text)
# Y ahora las puntuaciones
pts = soup.find_all('div', class_="value-puntuacion")
# Creamos un bucle que recorra cada elemento
for pt in pts:
p = pt.find('span')
puntos_pala.append(p.text)
puntos.append(puntos_pala)
time.sleep(0.3)
# Creamos un dataframe con toda la información
data = pd.DataFrame(puntos, columns = ('Modelo','Total','Potencia','Control','Salida de bola','Manejabilidad','Punto dulce'))
# Comprobamos
data
| Modelo | Total | Potencia | Control | Salida de bola | Manejabilidad | Punto dulce | |
|---|---|---|---|---|---|---|---|
| 0 | Bullpadel Hack 2019 | 8.60 | 9.00 | 8.00 | 9.50 | 8.50 | 8.00 |
| 1 | Royal Padel Whip Polietileno 2019 | 8.60 | 7.00 | 9.50 | 8.50 | 9.00 | 9.00 |
| 2 | Adidas Adipower 2.0 | 8.60 | 9.50 | 9.00 | 8.00 | 8.50 | 8.00 |
| 3 | Siux Diablo Granph | 8.60 | 9.00 | 8.50 | 8.50 | 8.00 | 9.00 |
| 4 | Siux Diablo Grafeno Azul | 8.60 | 9.50 | 8.00 | 8.50 | 8.50 | 8.50 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 583 | Adidas V6 | 5.90 | 5.00 | 5.50 | 6.50 | 7.00 | 5.50 |
| 584 | Adidas V7 | 5.90 | 5.00 | 5.50 | 6.50 | 7.00 | 5.50 |
| 585 | Adidas Match Light 3.0 2021 | 5.90 | 5.00 | 6.50 | 5.50 | 7.50 | 5.00 |
| 586 | Varlion LW One Soft 2018 | 6.10 | 5.00 | 6.00 | 6.00 | 7.50 | 6.00 |
| 587 | Bullpadel Libra 2018 | 6.10 | 5.00 | 5.50 | 6.00 | 8.00 | 6.00 |
588 rows × 7 columns
# Guardamos el dataframe en un excel
data.to_excel('puntos.xlsx',index=False)
Tras haber obtenido las puntuaciones, vamos a scrapear las características de las palas
Primero vamos a hacer algunas comprobaciones con una única pala como antes
url3 = 'https://padelzoom.es/siux-diablo-mate/'
# Hacemos el get requests para leer la información
page3 = requests.get(url3)
# Analizamos la información en formato html
soup = BeautifulSoup(page3.content, 'html.parser')
# Buscamos todas las etiquetas de la clase "text-title-price" que es el contenedor de la
# información que estamos buscando
caract = soup.find_all('div', class_="col-md-4 col-sm-6")
# Creamos listas vacías para almacenar la información
names = list()
caracteristicas = list()
# Creamos un bucle que recorra cada elemento de la lista webs
for cr in caract:
a = cr.find('span', property="name")
b = cr.find('div', class_="description-pala")
c = b.find_all('p')
for i in c:
caracteristicas.append(i.text)
caracteristicas
['Temporada : 2020',
'Material marco : Fibra de carbono 3K',
'Material plano : Fibra de carbono y aluminio',
'Material goma : EVA High Memory',
'Tacto : Medio-Duro',
'Forma : Diamante',
'Peso : 360-375 gramos']
# Creamos una función para eliminar la información que no necesitamos
def eliminar_puntos(lista):
return [l.split(' : ')[1] for l in lista]
eliminar_puntos(caracteristicas)
['2020',
'Fibra de carbono 3K',
'Fibra de carbono y aluminio',
'EVA High Memory',
'Medio-Duro',
'Diamante',
'360-375 gramos']
# Creamos una lista vacía para almacenar la información
caracteristicas = list()
# Y lanzamos el bucle para obtener las caracteristicas
for enlace in enlaces_palas:
url = enlace
page = requests.get(url)
# Analizamos la información en formato html
soup = BeautifulSoup(page.content, 'html.parser')
# Creamos uns lista vacía para almancenar la información de cada página, y que se vacie
# en cada visita a una web distinta
caract_pala = list()
# Buscamos todas las etiquetas de la clase "col-md-4 col-sm-6" que es el contenedor de la
# información que estamos buscando
caract = soup.find_all('div', class_="col-md-4 col-sm-6")
# Creamos un bucle que recorra cada elemento de caract
for cr in caract:
# Añadimos el nombre de cada pala en primer lugar
a = cr.find('span', property="name")
caract_pala.append(a.text)
# Y ahora las puntuaciones
b = cr.find('div', class_="description-pala")
# Creamos un bucle que recorra cada elemento
c = b.find_all('p')
for i in c:
caract_pala.append(i.text.split(' : ')[1])
# Añadimos a nuestra lista
caracteristicas.append(caract_pala)
time.sleep(0.2)
caracteristicas
[['Bullpadel Hack 2019',
'2019',
'Tubular 100% carbono + protector de aluminio',
'Xtend Carbon 18K',
'Black EVA',
'Medio-Blando',
'Diamante',
'365-380 gramos'],
['Royal Padel Whip Polietileno 2019',
'2019',
'Tubular bidireccional de fibra de vidrio con refuerzos de tejido de carbono.',
'Tejido de vidrio aluminizado. Impregnación de resina epoxi incluyendo dióxido de titanio',
'Polietileno de alta densidad',
'Medio-Blando',
'Redonda',
'360-385 gramos'],
['Adidas Adipower 2.0',
'2020',
'Fibra de carbono 3K',
'Fibra de carbono y aluminio',
'EVA High Memory',
'Medio-Duro',
'Diamante',
'360-375 gramos'],
['Siux Diablo Granph',
'2019',
'Carbono + Grafeno',
'Carbono + Grafeno',
'EVA Soft',
'Medio-Duro',
'Lágrima',
'360-375 gramos'],
...
...
['Adidas V7',
'2020',
'Fibra de carbono',
'Fibra de vidrio',
'EVA Soft',
'Medio-Blando',
'Lágrima',
'360-375 gramos'],
['Adidas Match Light 3.0 2021',
'2021',
'Fibra de vidrio',
'Fibra de vidrio',
'EVA Soft',
'Medio-Blando',
'Diamante',
'350-360 gramos'],
['Varlion LW One Soft 2018',
'2018',
'Fibra de vidrio',
'Fibra de vidrio',
'SYL Core',
'Medio',
'Redonda',
'325-355 gramos'],
['Bullpadel Libra 2018',
'2018',
'Tubual 100% Carbono',
'Polyglass',
'Evalastic',
'Medio-Blando',
'Redonda',
'350-360 gramos']]
# Creamos un dataframe con toda la información
data_caract = pd.DataFrame(caracteristicas, columns = ('Modelo','Temporada','Material Marco','Material plano',
'Material goma','Tacto','Forma','Peso'))
# Comprobamos
data_caract
| Modelo | Temporada | Material Marco | Material plano | Material goma | Tacto | Forma | Peso | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bullpadel Hack 2019 | 2019 | Tubular 100% carbono + protector de aluminio | Xtend Carbon 18K | Black EVA | Medio-Blando | Diamante | 365-380 gramos |
| 1 | Royal Padel Whip Polietileno 2019 | 2019 | Tubular bidireccional de fibra de vidrio con r... | Tejido de vidrio aluminizado. Impregnación de ... | Polietileno de alta densidad | Medio-Blando | Redonda | 360-385 gramos |
| 2 | Adidas Adipower 2.0 | 2020 | Fibra de carbono 3K | Fibra de carbono y aluminio | EVA High Memory | Medio-Duro | Diamante | 360-375 gramos |
| 3 | Siux Diablo Granph | 2019 | Carbono + Grafeno | Carbono + Grafeno | EVA Soft | Medio-Duro | Lágrima | 360-375 gramos |
| 4 | Siux Diablo Grafeno Azul | 2019 | Carbono + Grafeno | Carbono | Black EVA Soft | Medio-Duro | Lágrima | 360-375 gramos |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 583 | Adidas V6 | 2019 | Fibra de carbono | Fibra de vidrio | EVA Soft | Medio-Blando | Lágrima | 360-375 gramos |
| 584 | Adidas V7 | 2020 | Fibra de carbono | Fibra de vidrio | EVA Soft | Medio-Blando | Lágrima | 360-375 gramos |
| 585 | Adidas Match Light 3.0 2021 | 2021 | Fibra de vidrio | Fibra de vidrio | EVA Soft | Medio-Blando | Diamante | 350-360 gramos |
| 586 | Varlion LW One Soft 2018 | 2018 | Fibra de vidrio | Fibra de vidrio | SYL Core | Medio | Redonda | 325-355 gramos |
| 587 | Bullpadel Libra 2018 | 2018 | Tubual 100% Carbono | Polyglass | Evalastic | Medio-Blando | Redonda | 350-360 gramos |
588 rows × 8 columns
# Guardamos el dataframe en un excel
data_caract.to_excel('caracteristicas.xlsx',index=False)
Con esto ya tenemos nuestra base de datos de palas. Ahora ya podemos hacer análisis o algún algoritmo, pero eso lo dejamos para un siguiente artículo.